
Anomaly Detection is the process of identifying the items, occurrences, observations, or events that do not conform to the expected data pattern due to their contrary characteristics from the majority of the data. The term Anomaly is derived from the Greek word which means abnormality or exception. Anomalies in data are also called outliers, noise, or exceptions. Anomaly detection is the problem of finding the patterns in the data that do not conform to normal behavior. Anomalies in the data occur very infrequently and the characteristics of the anomaly are significantly diverse from all the other sets of data. Anomaly detection recently attracted the research field because of its applications and is highly popular in real-life situations. It is used extensively in the detection of fault in manufacturing, fraud detection financial transactions, construction anomalies, network problems, disturbance detection, system health monitoring, and many more.
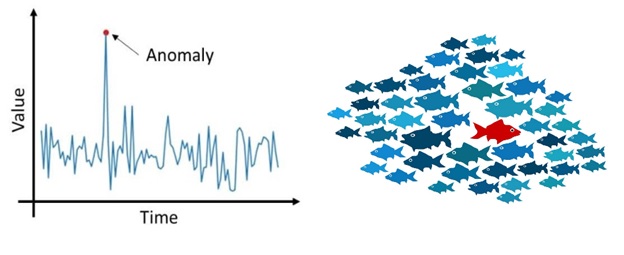
The anomaly can be of two types namely univariate and multivariate. Univariate anomalies can be found in the single-dimensional space and Multivariate anomalies can be found in the n-dimensional space. In the case of n-dimensional space finding the anomalies can be difficult that is why we need to train the models to do. The anomalies can also be in different flavors, that is Point anomalies, Contextual anomalies, and Collective anomalies. Point anomalies – if the single point deviates from the rest of the observations. For example, noticing the credit card fraud based on the amount spent. Contextual anomalies can be context-specific for example purchase during the festival season is normal otherwise may be odd. The third one is Collective anomalies can be the set of data instances that can help in detecting anomalies. Single data points looked at in isolation appear normal but when looked at a group of these data points unexpected results or patterns become clear. An example of a collective anomaly is the breaking of rhythm in electrocardiograms.
Anomalies in data can be detected by different data mining algorithms. Usually, algorithms fall into two categories i.e supervised learning and unsupervised learning. Some of the techniques which are used to detect the anomalies are density-based method –KNN, isolation Forest, Cluster analysis-k means and so on, Neural networks, LSTM networks, support vector machines, hidden Markov models, Bayesian networks, etc.
Off late social media has become part and parcel of human lives, as people with similar interests and values communicate and interact with each other. The people visit the different social media networks that include Twitter, Facebook, Instagram, MySpace that create social and professional networks. The popularity of social media raised a new type of anomalous behaviors that caused the various concerns of parties. Social network anomalies are unusual and illegal user activities. The anomalous messages on social networks will create a negative impact on society.
Anomaly detection is very crucial and it is used to detect the exceptional data point. Data scientists will put a lot of work to analyze the data and use various techniques that will make the data more safe and secure. We can conclude that detecting anomalies in business data and the following analysis can lead to practical identification and faster resolution of serious problems in the business area and that will lead to new business insights.
Prof Roopa U
Assistant professor,
DSCE – MBA